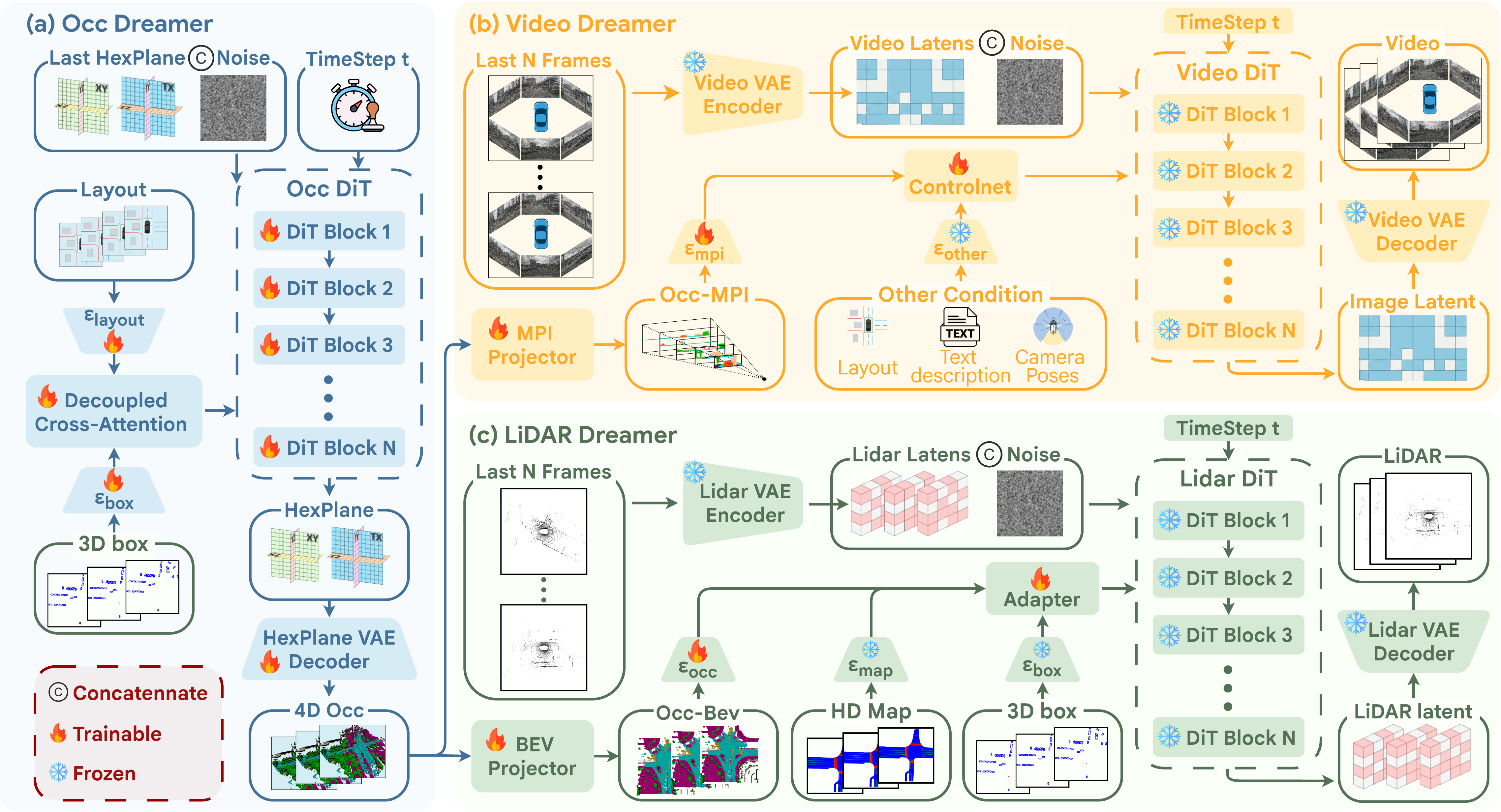
Unified 4D Occupancy State
Dynamic semantic occupancy serves as the explicit world state, making spatial structure and temporal evolution controllable.
Read the paper summary and motivation.
OverviewSee the core design choices and contributions.
MethodBrowse the diagrams and qualitative visualizations from the paper.
GalleryWatch the qualitative result video directly on the page.
VideoOpen the camera-ready manuscript directly in the page.
DocumentCopy the citation block for referencing.
CitationThe generation of realistic, consistent, and controllable multi-modal data for dynamic driving scenes remains a crucial challenge in autonomous vehicle simulation. Current methods often struggle to maintain geometric and temporal coherence, particularly when synthesizing complex interactions across disparate modalities, such as LiDAR and video. In this paper, we propose a novel cascaded autoregressive framework to generate highly realistic and multi-modally aligned driving scenes. The key innovation of this work is the utilization of dynamic occupancy as a unified and explicit intermediate representation. The proposed framework operates in two stages: first, the system generates a coherent sequence of controllable dynamic occupancy grids that capture the spatiotemporal geometry of the scene. Second, conditioned on the generated occupancy prior, two specialized diffusion models autoregressively synthesize the corresponding LiDAR point clouds and camera videos. By anchoring the generation of all modalities to a shared geometric foundation, the proposed model inherently ensures cross-modal consistency and temporal stability. Extensive experiments demonstrate that the proposed approach significantly outperforms state-of-the-art methods in terms of generation fidelity, geometric accuracy, and long-term temporal coherence for both LiDAR and video synthesis, paving the way for high-fidelity and multi-modal simulation.
Dynamic semantic occupancy serves as the explicit world state, making spatial structure and temporal evolution controllable.
The state sequence is generated autoregressively to preserve object permanence and temporal continuity over extended scenes.
Conditioned on the same occupancy prior, dedicated LiDAR and video generators remain geometrically aligned and temporally stable.
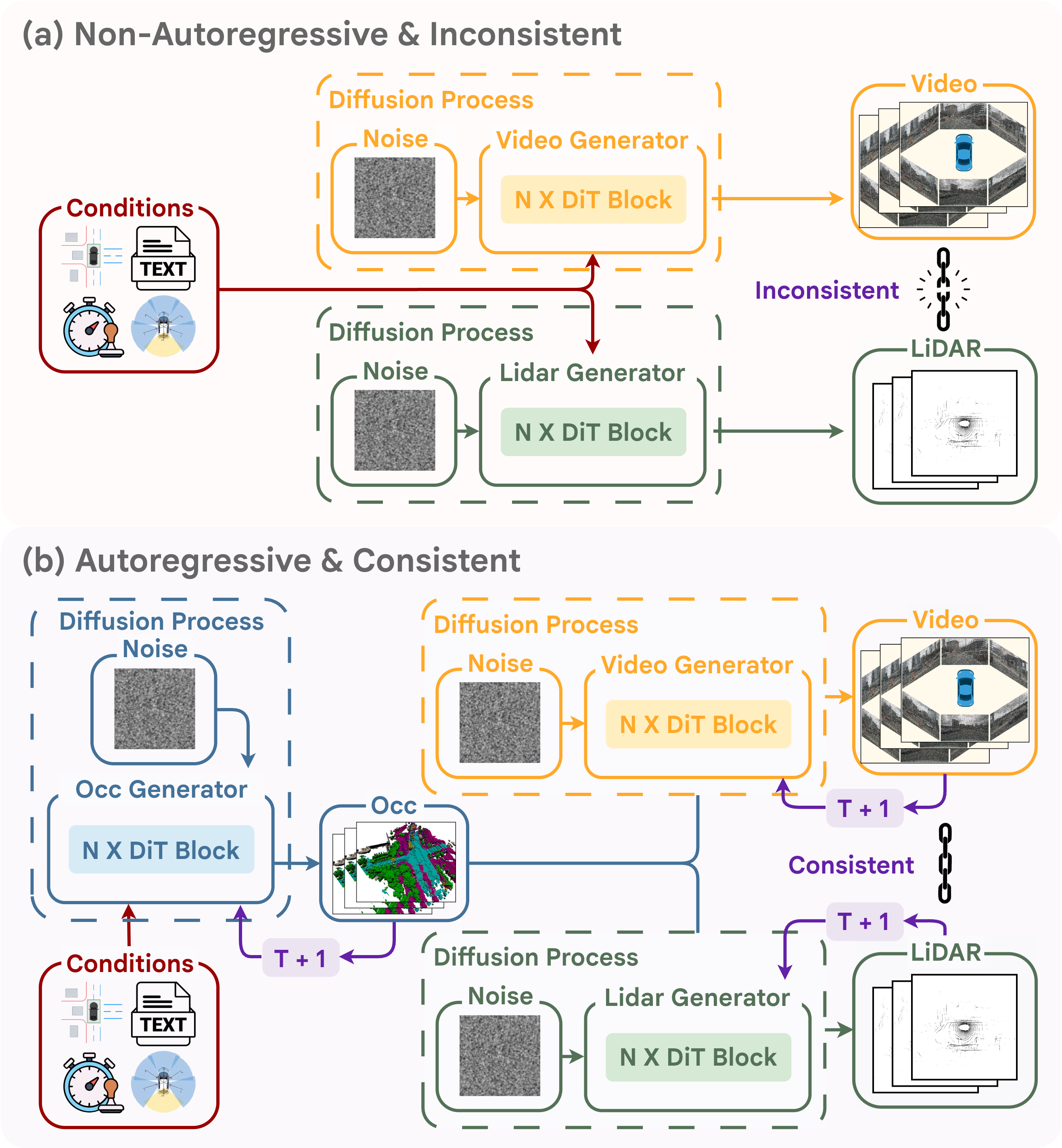
Overview figure highlighting Drive-Cascade's autoregressive occupancy-to-sensor generation pipeline.
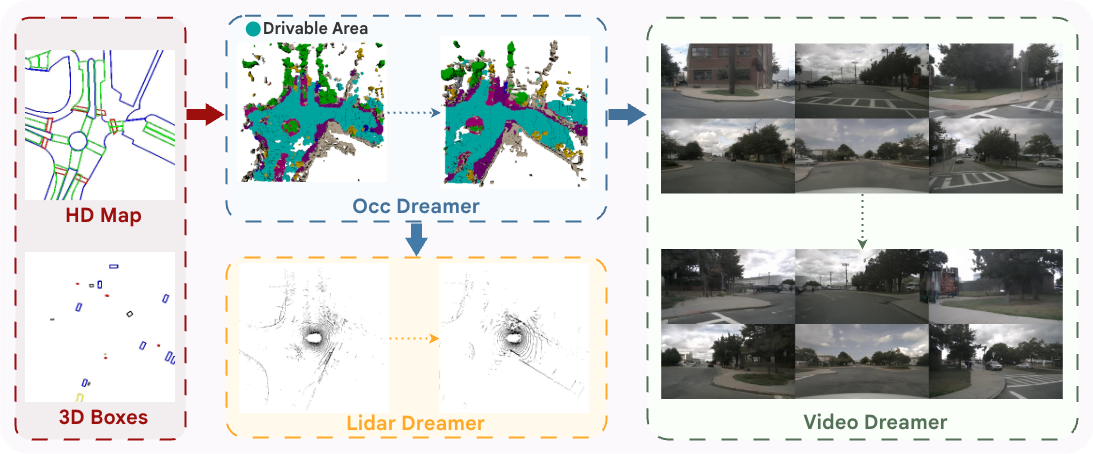
Combined qualitative comparison highlighting coherent multi-modal generation.
@article{lei2026drivecascade,
title={Drive-Cascade: Autoregressive Occupancy to LiDAR and Video Synthesis},
author={Lei, Shuangming and Huang, Yuehao and Yao, Yi and Xie, Yijia and Wang, Jingke and Wang, Ruoyu and Lv, Jiajun and Xu, Guanglin and Ye, AiXue and Liu, Bingbing and Cheng, Siyuan and Zhang, Hongbo and Ma, Yukai and Liu, Yong},
journal={CVPR 2026 Findings},
year={2026},
url={https://summersray.github.io/Drive-Cascade/}
}